

метод огляд
Після послідовність-к-структури на функцію парадигми, I-TASSER процедуру 1-4 для структури і функції моделювання включає в себе чотири послідовних стадії: (а) шаблон ідентифікації LOMETS 5, (б) фрагмент структури збірки на репліку- обмін Монте-Карло 6; (С) уточнення структури атомного рівня, використовуючи REMO 7 і FG-MD 8, і (г) структури основі функції інтерпретації використанням кофактора 9.
Шаблон ідентифікації: для запиту послідовність представлених користувачем, послідовність перших різьбові через представника PDB бібліотеки структуру локально встановлені LOMETS мета-Threading сервера. Threading є послідовність структури вирівнювання процедура, яка використовується для визначення шаблонів білків, які можуть мати подібні структури або містять аналогічні структурним мотивом, як запит білка. Для збільшення охоплення гомологічних Темплелі виявлень, LOMETS об'єднує безліч стан сучасних алгоритмів, що охоплюють різні різьби методологій. З іншого потокової програми мають різні системи скорингу і вирівнювання чутливості, якість створюваної потоками лави з кожним різьблення програми оцінюється нормованого Z-оцінка, яка визначається як: 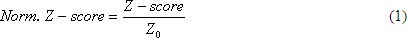
де Z-оцінка є оцінка в одиницях стандартного відхилення щодо середньостатистичної ціни всіх вирівнювання генеруються програмою, і Z 0 є конкретними програмами Z-рахунок відсічення визначається на основі великомасштабних потоків тестах 5 відрізнити «хороший» і «поганими» шаблони. Шаблону з високим Z-рахунок означає, що топ шаблони вирівнювання оцінка значно вище, ніж більшість інших шаблонів, який зазвичай означає, що вирівнювання відповідає гарною моделлю. Якщо велика частина верхньої різьблення шаблони пріветGH нормованого Z-оцінки, точність остаточного I-TASSER моделі, як правило, висока. Однак, якщо білок великих і охоплення різьблення вирівнювання зводиться до невеликої області запит білка, високу нормованого Z-оцінка не обов'язково означає високу точність моделювання для повнометражного моделі. Top дві різьблення ряди з кожним різьблення програми збираються і використовуються для наступного кроку структури збірки.
Ітераційні моделювання структури збірки: Після різьблення процедури запиту послідовність поділяється на потоки вирівняні і вирівняним регіонах. Безперервна фрагментів в потоки вирівнювання вирізали з шаблонів і використовувати безпосередньо для структури збірки, в той час вирівняним регіонах циклу побудовані на основі моделювання спочатку. Процедура структури Збірка здійснюється на решітці система керується репліки обміну Монте-Карло 6. I-TASSER силове поле включає в себе водень-бонахожденіі взаємодій 10, заснованої на знаннях статистичної точки зору енергії, одержуваної з відомих білкових структур в PDB-11, послідовний основі контактів з прогнозами SVMSEQ 12, і просторових обмежень зібрані з LOMETS 5 різьблення шаблонів. Конформаційні приманки генерується в низькотемпературної репліки під час моделювання згруповані по Spicker 13 для визначення структури низькою вільної енергією. Кластер центроїди верхньої кластерів отримані шляхом усереднення 3D-координати всіх кластерних структурних помилкових цілей і використовуються для остаточного покоління моделі. Моделювання та кластеризації процедуру повторюють ще два рази для видалення стеріческіх зіткнення і подальшого вдосконалення глобальної топології.
Атомна рівні побудови моделі і уточнення: кластер центроїди, отримані після Spicker кластеризації зводяться білка моделі (кожен залишок особі C α і бічного ланцюга центру мас) і ПрП. обмеженою біологічних додатків. Будівництво повної атомної моделі від моделей знижується здійснюється в два етапи. На першому етапі, REMO 7 використовується для побудови повної атомних моделей від C-альфа сліди за рахунок оптимізації Н-зв'язку мереж. На другому етапі, REMO повний атомних моделей додатково уточнені FG-MD 14, який покращує хребет торсіонних кутів, довжини зв'язків і бічного ланцюга орієнтації ротамер, по молекулярно-динамічного моделювання, а керуються структурні фрагменти з шукали PDB структур ТМ-вирівняти. FG-MD вишукані моделі використовуються в якості остаточної моделі для третинної структури прогнози по I-TASSER.
Якість створюваної моделі оцінюються на основі показник достовірності (C-рахунок), який визначається на основі Z-рахунком LOMETS різьблення вирівнювання і зближення I-TASSER моделювання, математично сформулювати так: 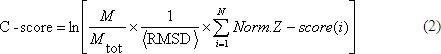
де 13; М малюк є загальна кількість помилкових цілей представлені кластеризації; середня СКО кластерних приманки в кластер центроїди; Norm.Z-Score (я) є нормованої Z-рахунок (рівняння 1) з верхньої різьблення вирівнювання отримана з я-й різьблення сервер в LOMETS 5; N є число серверів, використовуваних в LOMETS.
C-оцінка має сильну кореляцію з якістю I-TASSER моделей. Об'єднавши C-рахунок і білка довжини, точність перших I-TASSER моделей можна оцінити з Середня помилка 0,08 для ТМ-оцінка і 2 Å для СКО 15. Загалом, моделі С-оцінка> - 1.5 повинні мати правильну рази. Тут, СКО та ТМ-оцінка обидва добре відомі заходи топологічного подібності між моделлю і нативної структури. ТМ-оцінка ценниеес-діапазоні в інтервалі [0, 1], де вищий бал вказує кращої структурі відповідають 16,17. Однак для більш низьким рейтингом моделі (тобто 2-й моделі -5 е місце), співвідношення C-рахунок з ТМ-рахунок і СКО набагато слабкіше (~ 0,5), і не можуть бути використані для надійної оцінки абсолютної якості моделі.
Це перша модель завжди краща модель в I-TASSER симуляції? Відповідь на це питання залежить від типу мети. Для легкою мішенню, першою моделлю, як правило, найкраща модель і її C-оцінка, як правило, набагато вище, ніж інші моделі. Проте, для твердих мішенях, де потоки не мають значні хіти шаблон, перша модель не обов'язково найкраща модель, і я-TASSER насправді відчуває труднощі у виборі кращих шаблонів і моделей. У зв'язку з цим рекомендується, щоб проаналізувати всі 5 моделей для жорстких задач і виберіть їх на основі експериментальних даних і біологічних знань.
Функція PRED ictions: На останньому етапі, остаточний 3D-моделей, створених з FG-MD використовуються для прогнозування три аспекти функції білка, а саме: а) фермент комісія (ЄК) числа 18 і (б) Гена Онтологія (GO) 19 умов і (в) сайти зв'язування для малих лигандов молекули. Для всіх трьох аспектів, функціональні інтерпретації генеруються з використанням кофактором, який є новим підходом, щоб передбачити функцію білка, заснований на глобальному і локальному схожість з шаблоном білків в PDB з відомою структурою і функціями. По-перше, глобальної топології передбачив моделі порівнюється з функціональної бібліотеки шаблонів за допомогою програми структурних вирівнювання ТМ-20 вирівняти. Далі, набір білків найбільш близький до цільової моделі вибираються з бібліотеки на основі подібності їх глобальні структури, а також великий локальний пошук проводиться для визначення структури і послідовності схожість поруч активних / сайт зв'язування регіону. Результуюче глобальних і локальних оцінки подібності використовуються для ранжірованіяШаблон білків (функціональних гомологів) і передача анотації (ЄК номера і Джин Онтологія 19 термінів) на основі хітів скорингу. Крім того, зв'язування лігандів залишків сайті і зв'язування лігандів режимі виводяться на основі місцевих вирівнювання запит з відомими ліганд залишків сайту в топ забив шаблони функцій 9.
Якість функції (ЄС і GO термін) передбачення в I-TASSER оцінюється на основі функціональних оцінка гомології (Fh-рахунок), яка є мірою глобального і локального схожості між запитом і шаблон, і визначається як: 
де С-оцінка є оцінкою якості передбачив модель, як це визначено у формулі. (2); ТМ-оцінка заходів глобальні структурні подібності моделі і шаблони білків; СКО Алі СКО між моделлю і шаблон структури у відповідність структурно регіону від ТМ-20 вирівняти; Cov представляє охоплення структурних вирівнювання (тобто відношення структурно відповідність залишків, поділена на запит довжини); ID Алі ідентичності послідовності в ТМ-вирівнювання вирівнювання. Оцінками оцінка довіри до прогнозів ЄС кількість також включає в себе термін для оцінки відповідності активних сайтів (ACM) між запитом і шаблонів в межах певної локальної області, розраховується наступним чином: 
де N т являє собою кількість шаблонів присутніх відкладень в межах району, N Алі числа вирівняні запитів шаблон пари залишків, D II є відстань між C α я ю пару вирівняні залишків, D 0 = 3,0 А Відстань зрізу, M II є BLOSUM рахунків між г-й парі вирівнюються залишків. Загалом, FH-оцінка знаходиться в діапазоні [0, 5] і ACM оцінка становить від [0, 2], Де високі поділу вказують на більш впевнено функціональних обов'язків. ACM оцінка також використовується для оцінки локальної структури і послідовності схожість біля ліганд-зв'язуючі сайти, які називають BS-рахунок.
1. Подання білкової послідовності
- Відвідати I-TASSER веб-сторінки на http://zhanglab.ccmb.med.umich.edu/I-TASSER почати зі структурою і функцією моделювання експерименту.
- Скопіюйте та вставте послідовність амінокислот в надану форму або безпосередньо завантажити його з вашого комп'ютера, натиснувши кнопку "Огляд". I-TASSER сервер в даний час приймає послідовностей з до 1500 залишків. Білки більше ніж в 1500 залишків, як правило, декількома доменами білків, і рекомендуються повинен бути розбитий на окремі домени перед відправкою до I-TASSER.
- Вкажіть свою адресу електронної пошти (обов'язково) та назву роботи (за бажанням).
- Користувачі можуть додатково вказати зовнішній серед разрешеніемidue контакт / відстань обмеження, надбудови додаткових шаблонів або виключити будь-які шаблон білків в процесі моделювання структури. Детальніше про використання цих опцій в "Обговорення" розділі.
- Щоб уявити послідовність, клацніть на "Run I-TASSER" кнопку. Браузер буде спрямована на підтвердження сторінки, де відображуються вказаний користувачем інформації, робота ідентифікації (Іов ID) номер і посилання на веб-сторінку, де результати будуть здані на зберігання після завершення роботи. Користувачі можуть відзначати це посилання або запишіть номер завдання ідентифікації для подальшого використання.
2. Наявність результатів
- Перевірте стан вашого представлені роботи, відвідавши I-TASSER черзі сторінці http://zhanglab.ccmb.med.umich.edu/I-TASSER/queue.php . Натисніть на вкладку пошуку і використовувати номер ID Вакансії або послідовність запитів для пошуку на представлені роботи.
- Після структури і функції двіженіяdeling закінчено, повідомлення по електронній пошті, що містить образ передбачив структур і веб-посилання буде відправлений до вас. Натисніть на посилання або відкрити посилання в закладки Крок 1,5 переглядати і завантажувати результати.
3. Вторинна структура і розчинника прогнози доступності
- Перевірте FASTA відформатований послідовність запитів відображаються в верхній частині сторінки результатів. Якщо будь-які додаткові обмеження / шаблон був вказаний під час послідовності уявлення, що посилаються на веб-сторінці відображення зазначених користувачем інформацію також можна розглядати (рис. 1А).
- Вивчення вторинних передбачення структури відображаються у вигляді: альфа-спіралі (H), бета-нить (S) або котушки (C) і показник достовірності прогнозування (0 = низький, 9 = високий) для кожного залишку. Шукайте області з довгими відрізками регулярної вторинної структури (H або S) прогнози, оцінювати ядра регіону в білку. Структурні клас білків також можуть бути проаналізовані на основі розподілу елементів вторинної структури. Alтакім чином, довгі регіонів котушки елементи в білку зазвичай вказують неструктурованих / розупорядкованих областей.
- Подивитися передбачив розчинника доступності (рис. 1С) для визначення похований і розчинників піддається регіонів в запиті. Значення прогнозованих розчинника діапазоні доступності від 0 (похований залишок) до 9 (контакт залишку). Регіон містить в основному поховані залишки можуть використовуватися для позначення основних регіону в білку, а регіони з розчинником викрито і гідрофільні залишки є потенційними гідратації / функціональних сайтів.
4. Третинна структура прогнози
- Прокрутіть вниз, щоб подивитися передбачив третинної структури білка запиту, відображається в інтерактивному аплет Jmol (рис. 2). Клацніть лівою кнопкою миші на аплет для зміни зовнішнього вигляду відображаються структуру, збільшити в конкретному регіоні, вибрати конкретні типи залишків в передбачив модель або розрахувати між залишок відстані.
- Аналіз моделей на наявність довгих неструктурованих регіонах. Ці тegions зазвичай відповідають розупорядкованих областей в білок або вказують на відсутність шаблону вирівнювання. Ці регіони зазвичай мають низьку точність моделювання і видалення цих регіонах при моделюванні з N і С-кінцем регіоні покращиться моделювання точності.
- Завантажити PDB файли в форматі структури моделі, натиснувши на кнопку "Завантажити модель" посилання. Ви можете відкрити ці файли в будь-який молекулярної візуалізації програмного забезпечення (наприклад, PyMOL, Rasmol і т.д.) для подальшого аналізу структурних особливостей.
- Аналіз показник достовірності (C-оцінка) структури моделювання для оцінки якості передбачив структур. C-рахунок (рівняння 2) значення, як правило, в діапазоні [-5, 2], в якій високий бал відображає модель більш високої якості. Оцінками TM-рахунок і СКО першої моделі показаний як "Розрахункова точність Модель 1". Довгі білків, рекомендується для оцінки якості моделі на основі ТМ-рахунок, як ТМ-оцінка є більш чутливою до топологічних змін, ніж СКО. <LI> Натисніть на кнопку "Докладніше про C-оцінка", щоб проаналізувати C-рахунок, розмір кластера і кластера щільність всіх моделей. Розрахункова ТМ-рахунок і СКО представлені лише за перший I-TASSER моделі, так як С-рахунком з більш низьким рейтингом моделей не сильно корелює з ТМ-рахунок або СКО. Якість нижчим рейтингом моделі можуть бути частково оцінюється по їх щільності кластера і розмір кластера в порівнянні з першою моделлю, в якій моделі з великих кластерів і більш високою щільністю в середньому ближче до нативної структури.
- Низька оцінка C-прогнози зазвичай вказують низькі точність прогнозу. У більшості подібних випадків, запит білка не вистачає хороших шаблонів в бібліотеці і має розмір за межі неемпіричних моделювання (тобто> 120 залишків). У цих випадках користувачі можуть шукати додаткові просторові обмеження і використовувати їх для поліпшення I-TASSER моделювання (див. Обговорення розділу). Крім того, пропонується представити послідовності на наш сервер QUARK (QUARK / "> http://zhanglab.ccmb.med.umich.edu/QUARK/) для чистого моделювання неемпіричних якщо білок розміром менше 200 залишків.
5. LOMETS цільової шаблон вирівнювання
- Прокрутіть вниз, щоб проаналізувати десятку різьблення шаблони запитів білка, як це визначено LOMETS програм різьблення (рис. 3). Подивитися нормованого Z-рахунок (рівняння 1), показаному на 'Норма. Z-рахунок "стовпець, аналізувати якість різьблення вирівнювання. Траси з нормованою Z-оцінка> 1 відображає впевненість вирівнювання і, швидше за все, мають ті ж раз за запитом білка.
- Аналіз послідовності ідентичність в різьблення краю області ( «Іден. 1 'стовпець) і для всього ланцюжка (' Іден. 2 'колонка) оцінити відповідність між запитом і шаблон білків. Висока ідентичність послідовності індикатора еволюційного спорідненості між запитом і шаблон білків.
- Вид різьби вирівняні залишків показано на кольорові візуально визначити мінусиerved залишків / мотиви в запит і шаблон білків. Вище ідентичності послідовності в різьблення краю області, в порівнянні з цілісною ланцюга вирівнювання також вказує на присутність зберігається структурний мотив / доменів в запиті.
- Оцінка охоплення потоків вирівнювання, переглянувши 'Соу. колонки і перевірки вирівнювання. Якщо освітлення верхньої вирівнювання низька і обмежується лише невелика область запиту білка або був відсутній довгий сегмент запит послідовність, то запит білка зазвичай містить більше одного домену, тому рекомендується розбити послідовність і модель областей в індивідуальному порядку (рис. 3).
- Завантажити PDB відформатований послідовність структури файлів вирівнювання, натиснувши на "Завантажити Вирівнювання" посилання. Ці вирівнювання файл можна відкрити в будь-якій програмі молекулярної візуалізації, перераховані в розділі Матеріали, а також може бути використаний для додавання додаткових обмежень в структурі моделювання (крок 1.4).
6.Структурние аналоги в PDB
- Перегляд таблиці (рис. 4) в результаті сторінці, щоб визначити десятку структурних аналогів вперше передбачено моделлю, як це визначено програмою структурних вирівнювання ТМ-20 вирівняти. ТМ-оцінка> 0,5 означає, що виявлена аналогові і моделі, аналогічної топологією і може бути використана для визначення структурних класів / білок сімейства запит білка 16, а з ТМ-оцінка <0,3 означає випадкове подібність структури.
- Аналіз послідовності ідентичність і СКО в структурно вирівняні області, показаної на "IDEN» і «СКО» колони для оцінки збереження просторової мотиви в моделі і структурним аналогом. Огляньте кольорових і приведені у відповідність пар залишків в вирівнювання, щоб визначити ці структурно зберігаються залишки і мотиви .
- Натисніть на PDB код, вказаний в колонці "PDB Hit 'відвідати RCSB сайт і дізнатися більше про їх структурної класифікації (СКОП, CATH і PFAM) і функціональної інформації (ЄС номер, пов'язаний GO термінів і пов'язаного ліганда).
7. Функція прогноз за допомогою кофактора
- Прокрутіть сторінку результатів для аналізу функціональних інтерпретацій для запиту білка. Білки функції, перераховані в три таблиці контексті відображення: Фермент комісія (ЄК) номера, Джин Онтологія (ГО) умовах, і зв'язування лігандів сайтів.
- Подивитися "ТМ-оцінка», «СКО», «IDEN» і «Соу. Стовпців в кожній таблиці для аналізу параметрів глобального подібності структури і збереження просторових структур, між моделлю і визначені функціональні гомологів (шаблонів).
8. Фермент комісії номер прогноз
- Подивитися п'ятірку потенційних гомологів ферменту білка запиту показані в "Прогнозована ЄС номерів" таблиці (рис. 5). Рівня довіри ЄС кількість прогноз за допомогою цих шаблонів показано в стовпці "EC-Оцінка». На підставі benchmarking аналіз 23, функціональне схожість (перші 3 цифри числа ЄК) між запитом і шаблон білка може бути надійно інтерпретовані EC-оцінка> 1.1.
- Шукайте консенсус функції (ЄС номерів) серед шаблонів, які мають аналогічні рази (тобто ТМ-оцінка> 0,5) в якості запиту білка. Якщо кілька шаблонів мають однакову кількість ЄС і EC-оцінка> 1,1, рівень достовірності прогнозування є дуже високим. Однак, якщо ЄС показник високий, але є відсутність консенсусу між визначили хітів, то прогноз стає менш надійним і користувачам рекомендується проконсультуватися GO довгострокові прогнози.
- Натисніть на посилання, представлену на номери EC відвідати ExPASy бази даних ферментів і аналізувати функції, в тому числі реакції, що каталізує, супутнім фактором вимоги і метаболічний шлях, за шаблоном білка в деталях.
9. Онтологія гена (ГО) прогнози термін
- Подивитися "Прогнозована GO терміни" таблиці (рісЮр 6) визначити десятку гомологів запит білка в PDB бібліотеці, анотований з Джином Онтологія (ГО) умовах. Кожен білок, як правило, пов'язаний з декількома умовами GO, що описує його молекулярних функцій (МФ), біологічних процесів (БП) і клітинні компоненти (ГК). Натисніть на кожного члена, щоб відвідати веб-сайт Аміго і аналізувати її визначення та походження.
- Аналіз FH-оцінка (функціональна оцінка гомології) колонки для доступу до функціональних схожістю між запитом і шаблон білків і оцінити рівень достовірності передачі функціональної анотації з цих білків. У нашому порівняльного дослідження 23, 50% від рідних умовах GO може бути визначений невірно з вперше виявлено шаблонів за допомогою РН-рахунок відсічення 0,8, із загальною точністю 56%.
- Подивитися "Консенсус прогноз ГО терміни" таблиця для аналізу згоди функції між шаблонами. Ці загальні функції використовуються для прогнозування GO вираженні (MF, ВР і КС) запросбелка і оцінити рівень достовірності (GO-рахунок) ГО довгострокові прогнози. На основі тестування тест 23, кращий хибнопозитивних і помилково негативні темпи отримані для передбачення з GO-рахунок відсічення = 0,5, при зменшенні освітлення прогноз на більш глибокому рівні онтології.
10. Білок-ліганд прогнози сайт
- Прокрутіть вниз до нижньої частини сторінки, щоб подивитися в десятку ліганд прогнози сайт для запиту білка. Прогнозована сайти зв'язування ранжуються в залежності від кількості прогнозованих ліганд конформації, які мають спільні зв'язує кишені. Кращий сайт зв'язування визначені вже відображається в Jmol аплет. Натисніть на перемикач, щоб проаналізувати і інші прогнози і візуалізувати залишків ліганд взаємодіє.
- Аналіз BS-оцінка колонки для оцінки локального подібності між моделлю і сайт зв'язування шаблону. На підставі тестів 9, BS-оцінка> 1,1 вказує на високу послідовність і структура сімilarity біля передбачив сайт зв'язування в моделі і відомий сайт зв'язування в шаблоні.
- Завантажити файл у форматі PDB структура комплексу, натиснувши на посилання "Завантажити". Користувачі можуть відкрити ці файли в будь-яку молекулярну програму візуалізації та інтерактивного перегляду передбачив сайт зв'язування і ліганд-білкових взаємодій на своєму локальному комп'ютері.
11. Представник результати
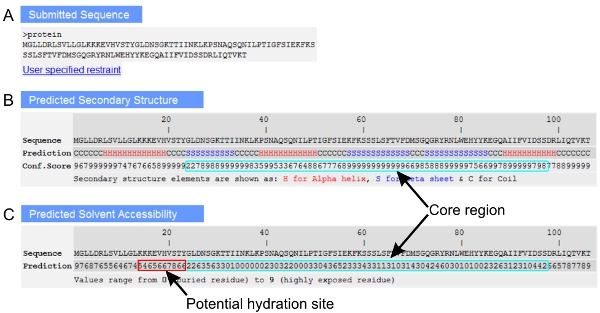
Малюнок 1 витяг з I-TASSER результаті сторінка, що показує () FASTA запиту в форматі послідовності ;. (B) передбачив вторинної структури і пов'язані з ними оцінки впевненості, і (C) передбачив розчинника доступності залишків. Аналізованої області ядра і потенційне місце гідратації в запиті виділені блакитним і червоним прямокутниками, відповідно.
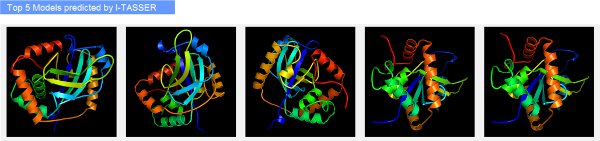
Малюнок 2.> Приклад I-TASSER результаті сторінка, що показує третинної структури прогнози для запиту білків. Передбачив моделі відображаються в інтерактивних аплет Jmol, дозволяючи користувачеві змінювати відображення молекули. Моделі також можна завантажити, натиснувши на кнопку "Завантажити" посилання. Показник достовірності оцінити якість моделі вказується як C-рахунок.
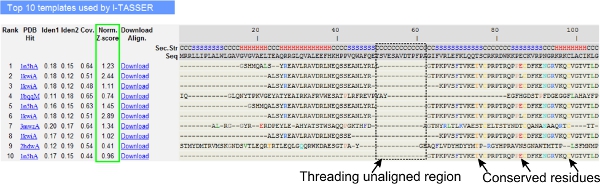
Малюнок 3. Приклад I-TASSER результаті сторінка, що показує десятку визначили різьблення шаблонів і вирівнювання по LOMETS 5 різьблення програм. Якість різьблення вирівнювання оцінюється на основі нормованих Z-рахунок (виділено зеленим), де значення> 1 відображає впевненість вирівнювання. Уніфіковані залишків в шаблоні, ідентичні відповідні відрахування будуть виділені фоновим для позначення присутності зберігається залишок / мотив, а відсутність узгодження в більшості топ шаблонів вказує на наявність декількох доменів в білку запит і вирівняним залишки відповідають областям домену компоновщика. Натисніть тут, щоб подивитися повнорозмірні версії малюнку 3.
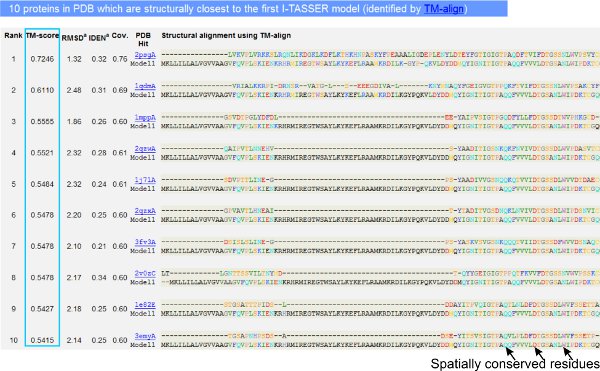
Малюнок 4. Приклад результату сторінка, що показує десятку визначили структурні аналоги і структурних трас, визначених ТМ-20 вирівняти структурні програми вирівнювання. Рейтинг аналогів показано на засноване на ТМ-оцінка (виділені синім) структурного вирівнювання. ТМ-оцінка> 0,5 вказує, що два порівнюваних структур аналогічну топологію, а ТМ-оцінка <0,3 означає подібність між двома випадковими структурами. Структурно відповідність пар залишків виділяються кольором залежно від їх амінокислотного власності, в той час як вирівняним регіонах, позначені «-». Ove.com/files/ftp_upload/3259/3259fig4large.jpg "> Натисніть тут, щоб подивитися повнорозмірні версії малюнку 4.
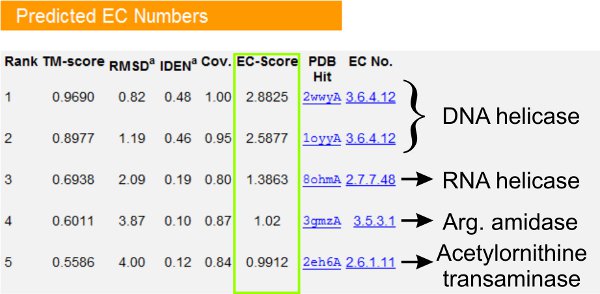
Малюнок 5. Приклад I-TASSER результаті сторінка, що показує визначені ферменту гомологів запит білка в PDB бібліотеки. Рівень достовірності прогнозування числа ЄС, аналізується на основі ЄС-оцінка (виділені зеленим кольором), де EC-оцінка> 1,1 вказує функціональне схожість (ті ж перші 3 цифри числа ЄК) між запитом і шаблон білка.
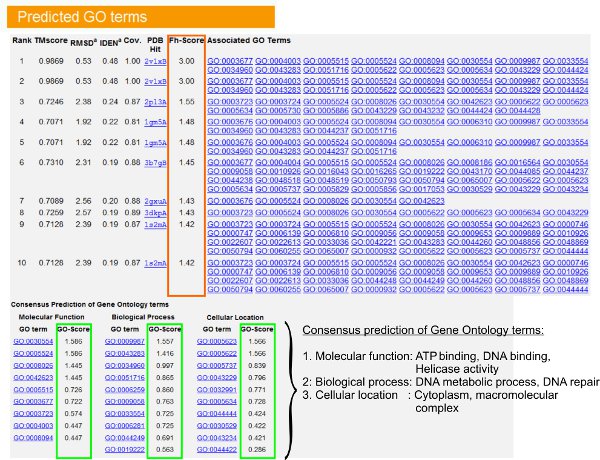
Малюнок 6. Приклад I-TASSER результаті сторінка, що показує GO довгострокові прогнози для запиту білка. Функціональні гомологів для запиту білка в бібліотеку шаблонів Онтологія гена оцінюються на основі їх Fh-рахунок (в прямокутник оранжевого кольору). Загальні функціональні особливості цих топ-скорингу хітів виводяться на GENER їли остаточного GO довгострокові прогнози для запиту білка. Якість передбачив GO умов визначається на основі GO-оцінка (показані зеленим кольором), де GO-оцінка> 0,5 вказує надійні передбачення. Натисніть тут, щоб подивитися повнорозмірні версії малюнку 6.
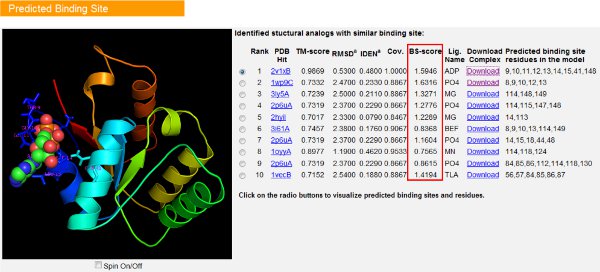
Малюнок 7. Приклад I-TASSER результаті сторінка, що показує десятку білок ліганд прогнози сайт за допомогою кофактора 9 алгоритму. Рейтинг передбачив сайти зв'язування на основі числа передбачили ліганд конформації, які мають спільні зв'язує кишені в запиті. BS-оцінка (виділено червоним) є мірою місцевих послідовність і структура схожість між передбаченим і сайт зв'язування шаблону, а також корисний при аналізі збереження обов'язкових кишені сайту.
les / ftp_upload / 3259 / 3259fig8.jpg "/>
Малюнок 8. Приклад зовнішніх файлів стриманість використовується для для визначення залишків залишків контакт / відстань обмежень.

Малюнок 9. Приклад стриманості файлів, використовуваних для визначення шаблонів білка I-TASSER сервера. Користувач може вказати запит-шаблон вирівнювання або в () FASTA форматі, або (B) 3D-форматі.
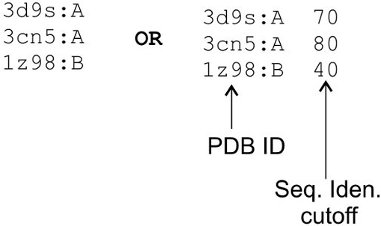
Малюнок 10. Приклад файлу, використовуваного для виключення шаблону під час I-TASSER процедура моделювання структури. Перший стовпець містить PDB ідентифікатор шаблону білки повинні бути виключені. Друга колонка використовується для вказівки відсічення ідентичності послідовності, яка буде використовуватися для інших подібних шаблонів в бібліотеку шаблонів.
